|
Untitled Document
|
ICI Deep Web Intelligence Center
Search on the Internet
 Searching on the Internet today can be compared to dragging a net across the surface of the ocean. While much can be gathered from the top, there is a wealth of information that lies deeper, and therefore is missed by the average person. Searching on the Internet today can be compared to dragging a net across the surface of the ocean. While much can be gathered from the top, there is a wealth of information that lies deeper, and therefore is missed by the average person.
There are literally hundreds of billions of highly valuable documents hidden in searchable databases that cannot be retrieved by conventional search engines. The reason is simple: basic search methodology and technology has not evolved significantly since the inception of the Internet.
Traditional search engines create their card catalogs by "spidering" or crawling "surface" Web pages. To be identified, a page must be static and linked to subsequent other pages. Utilized in this manner, standard search engines cannot "see" or retrieve content in the Deep Web and the crawlers used by them cannot probe beneath the surface. The result is that enormous amounts of data remains untapped and effectively "hidden" to the crawler, while in reality, the material is in plain sight.
The Deep Web
The discovery of the Deep Web is the result of groundbreaking search technology developed by the Intelligence Community. Private companies have only recently developed search technology capable of identifying, retrieving, qualifying, classifying and organizing "deep" and "surface" content from the World Wide Web.
The Deep Web is qualitatively different from the surface Web. Deep Web sources store their content in searchable databases that only produce results dynamically in response to a direct request. But a direct query is a "one at a time" laborious way to search.
Our search system automates the process of making dozens of direct queries simultaneously using multiple thread technology. It allows searchers to dive deep and explore hidden data simultaneously from multiple sources using directed queries.
Businesses, researchers and consumers now have access to the most valuable and hard-to-find information on the Web and can retrieve it with pinpoint accuracy. If the most coveted commodity of the Information Age is indeed information, then the value of Deep Web content is immeasurable.
Deep Web searches are intended for cases where historic data (more than four years) needs to be obtained and which otherwise tends to "fall off" current-day data tables.
When conducting Deep Web intelligence studies on companies or individuals, we access a much different class of documents. Included in the search results are not only the standard information retrieved by conventional search engines but many other possible leads.
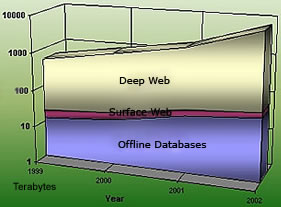
To put these numbers in perspective, we estimate that some of the largest search engines, such as Northern Light, individually index only 16% of the surface Web. Since they are missing the Deep Web, Internet searchers are therefore searching only 0.03% - or one in 3,000 - of the content available to them today.
Clearly, simultaneous searching of multiple surface and Deep Web sources is necessary when comprehensive information retrieval is needed.
We have automated the identification of Deep Web sites and the retrieval process for simultaneous searches. We have also developed a direct-access query engine translatable to about 20,000 sites, already collected, eventually growing to 100,000 sites. Our experience has shown that when the hit scores fall below 65%, they are not deemed reliable and the hits tend to be unrelated to the target of the inquiry. |
|
Highlights of Deep Web Search |
- Public information on the Deep Web that is 400 to 550 times larger than the commonly defined World Wide Web;
- 7,500 terabytes of information, compared to 19 terabytes of information in the surface Web;
- 550 billion individual documents compared to the 1 billion of the surface Web;
- Information from an addition 100,000 Deep Web sites;
- 60 of the largest Deep Web sites collectively contain about 750 terabytes of information - sufficient by themselves to exceed the size of the surface Web by 40 times;
- On average, Deep Web sites receive about 50% greater monthly traffic than surface sites and are more highly linked to than surface sites; however, the typical (median) Deep Web site is not well known to the Internet search public;
- The Deep Web is the largest growing category of new information on the Internet;
- Deep Web sites tend to be narrower with deeper content than conventional surface sites;
- Total quality content of the deep Web is at least 1,000 to 2,000 times greater than that of the surface Web;
- Deep Web content is highly relevant to every information need, market and domain. More than half of the deep Web content resides in topic specific databases;
- A full 95% of the deep Web is publicly accessible information - not subject to fees or subscriptions.
| |
|
*** Provisions of the Fair Credit Reporting Act, Bank Privacy Act, and other local, state, federal and international laws may apply to some searches. By placing any order with ICI, the client represents that the client has fully complied with all local, state, federal and international laws and assumes all responsibility. ICI assumes no responsibility for determining whether the client is in compliance with these laws. We are not a Consumer Credit Reporting Agency and all of our reports are done as an agent to counsel and protected under the Attorney Work-Product Doctrine, the Attorney-Client Privileged Communications Doctrine and other privileges. Please note that ICI can only be engaged by licensed attorneys and does not work for the general public or any local, state or federal governmental agency. We make no exceptions to this policy. If you are not a licensed attorney or are employed in any capacity by a local, state or federal agency, please exit the site at this time. By placing any order, inquiry, transmission, email, or download through this or any related site, you agree that you have fully read and agree to the Terms and Conditions as set forth by Investigative Consultants, Inc. |
Return to Top
|
Copyright
© 1995- Investigative Consultants, Inc. All Rights Reserved.
ARADS®, ColdChek™, DirectChek™, DockuChek®, EuroChek®, Global Scan®, IdentiChek®, IncomeTrust™, and TerrorChek® are Trademarks of Investigative Consultants, Inc. All Rights Reserved.
|































